The life cycle of a file transfer follows this basic pattern:

The first and last step in the diagram, Disk IO, were covered in Part 1 of the series: Improving Throughput Part 1: Disk IO. Disk IO is always a good place to start when analysing a system to see why files are not transferring fast enough.
In the 2nd article in this series, we’re going to concentrate on that white fluffy cloud—the transfer itself, over a WAN—and how we can adjust memory settings to attain faster speeds. Specifically, I want to look at what the following settings bring to the application:
- block size
- sender threads
- packet size
How much memory do I need, and how do I set it?
Part of the reason our protocol is able to achieve fast speeds in high latency environments is that it is able to handle large amounts of data “on the wire”, unlike traditional protocols like TCP.
To calculate the “theoretical minimum” memory required to saturate a link, you can follow this simple equation:
Minimum Memory (MB) = Bandwidth (Mb/s) × Latency (s)
8 (bytes per bit)
With this formula, 300mbps @ 150ms latency = 5.625 MB minimum of in-flight data as a baseline figure
However, that assumes that all packets arrive, on a perfectly clean link – with no traffic, no congestion control, and no hiccups along the way.
The reality is that you actually need a bit more memory. The “fudge factor” we like to employ is 2-3x more memory than “theoretical minimum” for regular links (up to 0.5% packet loss), and a larger value for higher packet loss (5-10× baseline in certain circumstances).
This table shows the memory required (3× baseline) by FileCatalyst software to send your data out at full speed:
| Amount of data (MB) in-flight required based on latency & bandwidth (minimum value * 3) | |||||||||||||
| Bandwidth (mbps) | Latency (ms) | ||||||||||||
| 1 | 2 | 5 | 10 | 25 | 50 | 75 | 100 | 150 | 200 | 250 | 300 | 350 | |
| 1 | 0.00 | 0.00 | 0.00 | 0.00 | 0.01 | 0.02 | 0.03 | 0.04 | 0.06 | 0.08 | 0.09 | 0.11 | 0.13 |
| 2 | 0.00 | 0.00 | 0.00 | 0.01 | 0.02 | 0.04 | 0.06 | 0.08 | 0.11 | 0.15 | 0.19 | 0.23 | 0.26 |
| 5 | 0.00 | 0.00 | 0.01 | 0.02 | 0.05 | 0.09 | 0.14 | 0.19 | 0.28 | 0.38 | 0.47 | 0.56 | 0.66 |
| 10 | 0.00 | 0.01 | 0.02 | 0.04 | 0.09 | 0.19 | 0.28 | 0.38 | 0.56 | 0.75 | 0.94 | 1.13 | 1.31 |
| 25 | 0.01 | 0.02 | 0.05 | 0.09 | 0.23 | 0.47 | 0.70 | 0.94 | 1.41 | 1.88 | 2.34 | 2.81 | 3.28 |
| 50 | 0.02 | 0.04 | 0.09 | 0.19 | 0.47 | 0.94 | 1.41 | 1.88 | 2.81 | 3.75 | 4.69 | 5.63 | 6.56 |
| 75 | 0.03 | 0.06 | 0.14 | 0.28 | 0.70 | 1.41 | 2.11 | 2.81 | 4.22 | 5.63 | 7.03 | 8.44 | 9.84 |
| 100 | 0.04 | 0.08 | 0.19 | 0.38 | 0.94 | 1.88 | 2.81 | 3.75 | 5.63 | 7.50 | 9.38 | 11.25 | 13.13 |
| 200 | 0.08 | 0.15 | 0.38 | 0.75 | 1.88 | 3.75 | 5.63 | 7.50 | 11.25 | 15.00 | 18.75 | 22.50 | 26.25 |
| 300 | 0.11 | 0.23 | 0.56 | 1.13 | 2.81 | 5.63 | 8.44 | 11.25 | 16.88 | 22.50 | 28.13 | 33.75 | 39.38 |
| 500 | 0.19 | 0.38 | 0.94 | 1.88 | 4.69 | 9.38 | 14.06 | 18.75 | 28.13 | 37.50 | 46.88 | 56.25 | 65.63 |
| 750 | 0.28 | 0.56 | 1.41 | 2.81 | 7.03 | 14.06 | 21.09 | 28.13 | 42.19 | 56.25 | 70.31 | 84.38 | 98.44 |
| 1000 | 0.38 | 0.75 | 1.88 | 3.75 | 9.38 | 18.75 | 28.13 | 37.50 | 56.25 | 75.00 | 93.75 | 112.50 | 131.25 |
| 2000 | 0.75 | 1.50 | 3.75 | 7.50 | 18.75 | 37.50 | 56.25 | 75.00 | 112.50 | 150.00 | 187.50 | 225.00 | 262.50 |
| 3000 | 1.13 | 2.25 | 5.63 | 11.25 | 28.13 | 56.25 | 84.38 | 112.50 | 168.75 | 225.00 | 281.25 | 337.50 | 393.75 |
| 5000 | 1.88 | 3.75 | 9.38 | 18.75 | 46.88 | 93.75 | 140.63 | 187.50 | 281.25 | 375.00 | 468.75 | 562.50 | 656.25 |
| 10000 | 3.75 | 7.50 | 18.75 | 37.50 | 93.75 | 187.50 | 281.25 | 375.00 | 562.50 | 750.00 | 937.50 | 1125.00 | 1312.50 |
The green represents the default memory configured by a HotFolder, while the blue shows situations requiring tuning. By default, a HotFolder utilizes 20MB of memory per connection (5 threads of 4MB each). You can see that out-of-the-box settings cover most standard connections/speeds. In fact, for slower connections with only moderate latency (50mbps & 50ms latency), you can safely tune back the memory use per connection without any loss of performance.
The trade-off is that the defaults are not appropriate for speeds in excess of 1 Gbps, which always require configuration of memory settings (size of blocks) and threads utilized for sending data.
Where do I set memory usage, and what does it mean?
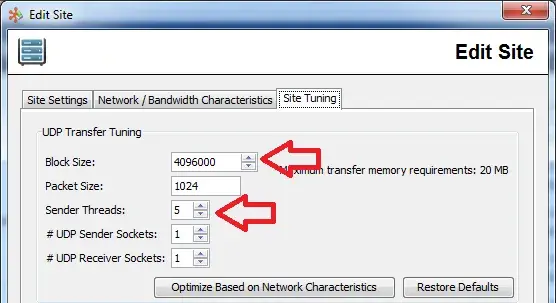
The FileCatalyst protocol works by first breaking files up into smaller blocks. The size of the blocks are completely user customizable. Out of the box, the HotFolder uses blocks of 4MB.
The application then schedules threads (Block Senders), who are responsible to pick up a file block (file section), and transmit them to the other side. Multiple threads implies multiple blocks can be sent concurrently.
A rough estimate of memory usage is:
memory used (MB) = block size (MB) × sender threads
On the HotFolder, this is set in the SITE configuration tab (enable “Advanced” view).
What is the advantage of using multiple threads? Why not 1 large 20MB block?
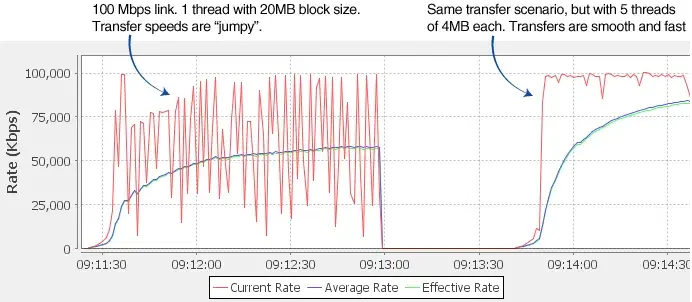
FileCatalyst’s UDP algorithm is designed to take advantage of multiple sender threads in order to maximize the link speed. Forcing a single thread to send data across tends to give “jumpy” bandwidth on links with higher packet loss and higher latency.
Here is an example of a 100 Mbps link with 300ms latency and packet loss of 1%. Two sets of tests were run: the first used 20MB of memory with a single thread, the second used 5 threads of 4MB each. After configuring 5 threads per transfer, with 4MB in size (on the right), the transfer speeds are smoother:
What does Packet Size bring to the equation?
FileCatalyst protocol is about breaking down large items (files) into smaller more manageable pieces (blocks), and transferring those one small piece at a time (packets).
The size of the packet sets the upper limit size that each packet can have on the network. If a file or a block is too big to fit in one packet, it is broken up into multiple packets and sent off the wire.
The benefit of a smaller packet is that it will work on all systems and networks. Some networks are known to NOT fragment packets, and simply drop packets larger than a set size.
The downside of smaller packets is that since the application must call the kernel for every UDP sent out. The smaller the packets size, the more packets are created, the more overhead the system must undertake in order to send the same data out.
To get more out of your CPU, jumbo frames (9000 Byte packets) are recommended.
For both these tests, I’ve set the following values on a 10 Gbps network:
- Link speed: 10 Gbps
- Latency: 50ms
- Packet loss: 0.5% each direction
Application settings:
- Block size: 20MB
- Sender threads: 20
- # UDP Sender sockets: 5
- # UDP Receiver sockets: 2
First, let’s have a look at mini frames (MTU=540, packet size=512):
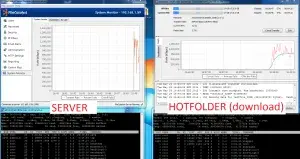
What you’re seeing is a high load system (230+% CPU) for the speed we’re sending at, and a very erratic transfer speed. The bottleneck (which is not easily identified) is kernel-level locks trying to send out all those tiny packets. In this run, the system is limited to ~700 Mbps despite having a fast network and fast disks.
Same test, same configurations. This time however, we modify the packet size to be our known MTU size (9K frames). Packet size should always be MTU – 28 bytes (required for FileCatalyst block headers).
Now with jumbo frames (MTU=9000 bytes, packet size=8972):
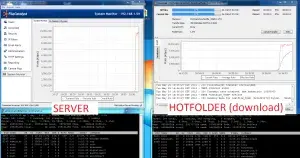
There we go! Full 10 Gbps speeds, with the CPU consumption within the same range (200-350%).